Case study · Research · Medical device
ColonMatcher: teaching a matcher to see inside the colon
A self-supervised way to adapt deep matchers to the colon without ground truth — and to stretch SLAM from a few stray seconds to a whole-colon reconstruction.
−65%
trajectory error (ATE) vs. classical SLAM
Seconds → 5 min
from stray clips to a whole colon
No ground truth
self-supervised training
Colorectal cancer is the second-deadliest cancer in the world, and colonoscopy is the reference tool for catching it early — yet up to 1 in 4 adenomas are missed. A visual SLAM that reconstructs the colon in 3D and measures which regions have actually been inspected attacks that gap head-on.
EndoCartoScope (a Horizon Europe project coordinated by the University of Zaragoza) builds SLAM-equipped smart endoscopes to do exactly that. In my master’s thesis I went after the last classical block left in its pipeline: the feature matcher. The result is ColonMatcher, a deep-learning matcher adapted to the colon with a self-supervised method that needs no ground truth. Paper on the way.
The challenge: the colon breaks classic SLAM#
The colon is one of the harshest environments there is for computer vision: deformable tissue that moves on its own, textureless walls, specular highlights, fluids, and a camera that moves fast and up close. Under those conditions classic matchers cannot find stable points to track between frames, and SLAM fragments into clips a few seconds long.
EndoCartoScope’s system (ECS-SLAM) had already swapped almost every classical block for a learned component. The feature matcher was the last one left untouched. That was my target.
My contribution: ColonMatcher#
The problem with adapting a matcher to the colon is that there is no ground truth: no one hands you the correct correspondences between two frames of a real colonoscopy. My solution is a three-stage self-supervised training curriculum. The first two stages teach matching from synthetic and 3D data; the third — the core contribution — specializes it on the colon.
In that third stage I use a powerful but slow dense model (RoMa) as a frozen “teacher”: over real colonoscopy sequences (EndoMapper), RoMa generates pseudo-ground-truth — which correspondences are reliable and which are not — with no real pose or depth. I fine-tune LightGlue on those labels to get ColonMatcher. The method is extractor-agnostic: the same recipe works for other detectors and other endoscopic modalities.
The key idea: turn a slow dense model into the teacher of a fast sparse one. I learn from the best available matcher without paying its real-time cost — and without a single hand-labelled example.
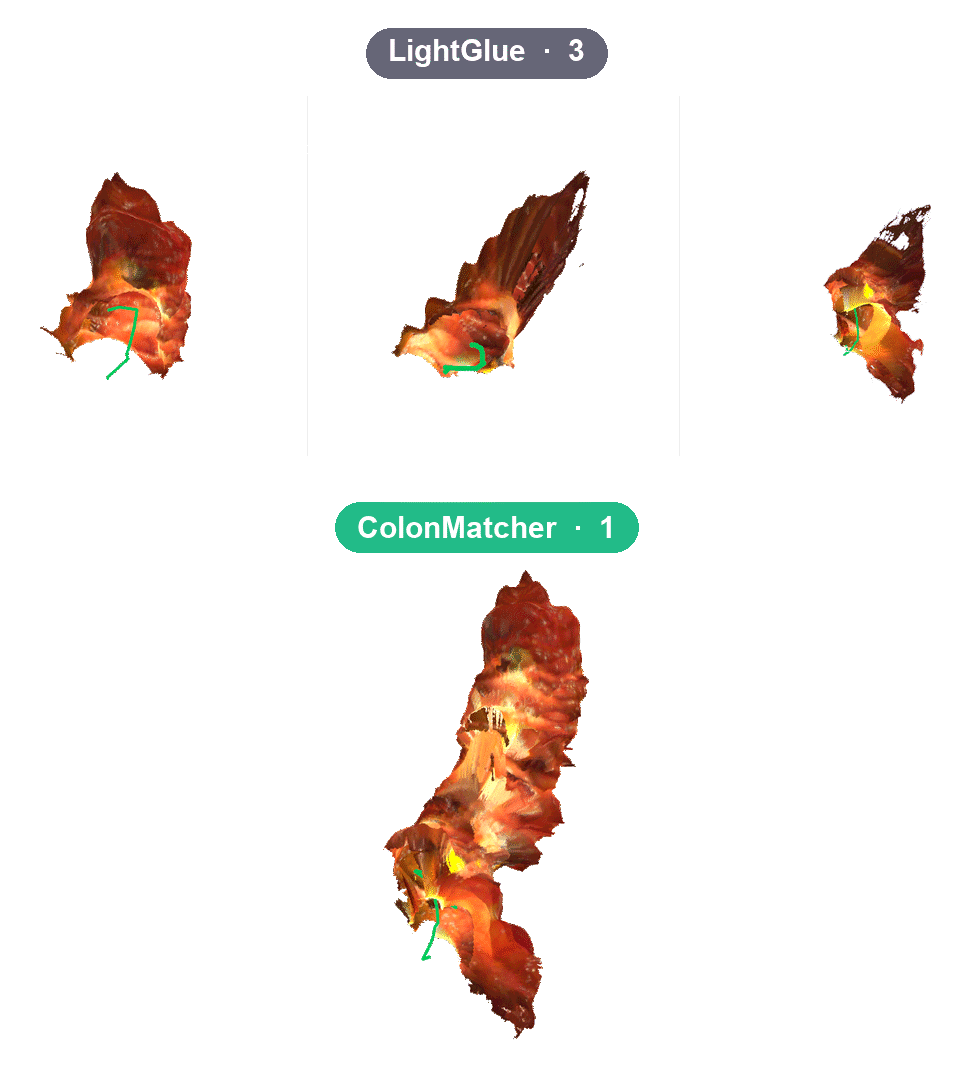
Results: from stray seconds to a whole colon#
I evaluated the system inside ECS-SLAM on 20 real colonoscopy sequences (EndoMapper), comparing the classical pipeline, out-of-box LightGlue, and my ColonMatcher. Swapping in learned matching and then adapting it to the domain stack up: the system goes from tracking 16 of 20 sequences to completing all 20.
Against the classical baseline, trajectory error (ATE) drops from 6.59 to 2.29 mm, map accuracy from 63 to ~1.5 mm, and tracking coverage from 40% to 99%. But the result I care about most is qualitative: on full withdrawals, ColonMatcher keeps tracking far longer and reconstructs whole segments in a single coherent map, where the system used to shatter into dozens of disconnected fragments.
ATE 6.59 → 2.29 mm; map accuracy 63 → ~1.5 mm; coverage 40% → 99%.
20/20 sequences completed, vs 16/20 for the classical pipeline.
On a full withdrawal: 119 → 86 submaps and 206 → 478 relocalizations — more colon in one map.
Stack#
Frequently Asked Questions#
What is EndoCartoScope?
A Horizon Europe project (EIC Transition, coordinated by the University of Zaragoza) developing SLAM-equipped smart endoscopes for 3D localization and mapping in colonoscopy. My master’s thesis contributes the matcher in its vision pipeline.
What is ColonMatcher?
My self-supervised adaptation of LightGlue to the colon. It uses a dense teacher (RoMa) to generate pseudo-ground-truth on real colonoscopies — no pose, no depth — and fine-tunes the matcher on it. It is extractor-agnostic.
Does it work for other endoscopies, or only the colon?
Yes: the training uses nothing colon-specific. It only needs a dense teacher (RoMa) to generate labels on the target images, so the same recipe can be retrained for other endoscopic modalities — and even with other feature extractors.
How much does it improve things?
On 20 real EndoMapper sequences, the system completes all 20 (up from 16), drops ATE from 6.59 to 2.29 mm and, above all, reconstructs much longer segments in a single coherent map. Paper on the way.